
The Ethereum Foundation recently announced a formal verification effort for RISC-V ZKVMs, in a landscape where these VMs are increasingly popular, with at least four companies currently developing one.
After years of development of EVM-specific ZKVMs by Polygon, ZKSync, Scroll, and others, one might think the Ethereum Foundation is taking a somewhat counterintuitive approach in this case. It raises the question of whether “RISC-V” has “won” in some sense—though what exactly constitutes “winning” is open to interpretation.
We thought this would be a good time to share our perspective on RISC-V ZKVMs, both the advantages and the drawbacks. In the end, we’ll circle back to what this may mean for the Ethereum Foundation.
Clearly, RISC-V ZKVMs let you move fast
Since RiscZero’s pioneering initial release of their VM, general-purpose ZKVMs based on RISC-V have surged in popularity.
This model involves compiling user code to an Instruction Set Architecture (ISA), which represents and provides an API to the hardware capabilities of a CPU. While RISC-V is the most popular ISA in the current ZKVM space—used by Risc0, Succinct’s SP1, Nexus, and a16z’s Jolt—it’s not the only one. For example, o1Labs is developing a MIPS-based ZKVM.
It’s easy to see why this is popular: it’s an excellent way to get a proof going quickly.
So like if a programmer writes, like a Sudoku game or Mao the card game (..) and just compiles it, then it runs on top of this VM just like a ZK EVM might run Solidity bytecode, this runs RISC-V code. So (for) any C, C++ and Rust, the compiler compiles this down into the RISC-V ISA and then this runs inside this VM. It’s really like having a little like Arduino or micro controller that’s like attached and living inside your system, but it’s virtual and it can’t lie about what it does and also it still has the same kind of ZK properties where you can hide inputs and so forth, as well as hide the program. — Brian Retford
This development speed is a tremendous improvement over earlier proof development tools, which either required manually defining circuits to represent a computation, or using DSLs (e.g., Noir or Circom). While these DSLs have performance benefits, they are fundamentally limited by the arithmetic circuit model—a topic beyond the scope of this document, but one we touch on in the Lurk paper.
Furthermore, this model allows for the reuse of a vast amount of pre-existing code. As a developer, not only can I write my proofs in the language of my choice, but I can also recompile and reuse the rich ecosystem of libraries I already rely on. The same is true for nearly all aspects of the developer experience and tooling, which transplant seamlessly to a RISC-V ZKVM. This versatility enabled Risc0 to release a ZKEVM by recompiling an EVM as early as August 2023.
Can RISC-V VMs be performant enough? In most cases, yes, probably.
Some argue that the overhead introduced by ZKVMs is too high compared to custom proofs and point out that there will always be certain areas where going “under the hood” provides significant performance gains. These include for instance:
- non-deterministic approaches to computing pairings,
- non-deterministic methods for matrix multiplications, and
- non-deterministic techniques for curve arithmetic.
Because these non-deterministic approaches are both highly performant and cannot be easily represented in a model that translates high-level instructions mechanistically, they seem to demonstrate that ZKVMs will never fully eliminate the need for custom, performance-optimized circuits.
However, the ZK-proof community has recently realized that this is actually okay. Some modern RISC-V ZKVMs, like SP1, have adopted a precompile-centric architecture since April 2024. This approach combines the best of both worlds: it allows users to compile their code to RISC-V in most cases, while surgically extending the ISA with low-level circuits that accelerate performance-sensitive operations. This eliminates the VM overhead for the mission-critical parts of the code.
We were excited to see this approach implemented in SP1, as we had already introduced it in Lurk in December 2023. In fact, we were so impressed that we decided to use Sphinx, a variant of SP1, to power the initial releases of our light clients.
Can proofs based on a RISC-V VM be reproducible? Perhaps.
Why reproducibility matters
Let’s walk through the steps of what it would take for Alice and Bob to bet on the outcome of a game like ZK-Battleship on-chain, using a RISC-V ZKVM.
- One player needs to write a program that processes valid moves in the game and proves their resolution on the board (verifying hits and misses without revealing ship positions). In practice, this code would be written in a high-level language like Rust, which is the advantage of using a RISC-V ZKVM.
- Both players must agree that this program meets their expectations, and they must also agree on the ZKVM they want to use.
- Then, one player (say Alice) compiles the program to RISC-V, resulting in a RISC-V assembly that the VM can verify the execution of.
- Alice then writes a smart contract designed to verify valid proofs of execution of this RISC-V assembly on various inputs (e.g., valid player moves) and ensures the payout to the winner once the game concludes.
Concretely, this smart contract is parameterized with a verifying key specific to the RISC-V assembly program. This key is necessary because, without it, the smart contract could accept proofs from any RISC-V program and might not correctly assign rewards to the winner. For Bob to produce valid proofs for his Battleship moves—and trust that the proof corresponds to the original program agreed upon with Alice—he must independently reproduce this verifying key, which requires getting the exact same RISC-V assembly that Alice used.
Reproducible builds
This brings us to the challenge of reproducible compilation. What information (beyond the high-level program) must Alice and Bob share to achieve reproducibility?
- The RISC-V compilation target and exact ZKVM version is essential. RISC-V is not a single ISA but a family. Targeting the RV32I, RV32E, or RV64I standard base ISAs, along with the M, A, F, D, Q, C standard extensions, results in over 150 possible distinct ISAs—not to mention the emerging L, V, B, T, and P extensions, as well as some ZKVM-specific extensions. Thankfully, modern ZKVMs generally support just one specific instruction set each, so far.
- The exact choice and version of the compiler is crucial, as GCC and LLVM (to name two major implementations) can produce significantly different results from the same source.
- All compilation parameters are needed, as compilers often introduce difficult-to-reproduce environment values (e.g. file paths) into the produced assembly, unless using some fairly exotic compiler options.
However, this may not be sufficient:
- Most linkers produce results dependent on the linking order, which can vary across systems due to parallelism or differences in the filesystem’s directory walk order.
- Some compilers employ profile-guided optimizations.
- The time and locale of the compilation environments may influence the build.
- And so on.
The difficulty of achieving reproducible builds is well-known and documented by the Reproducible Builds project. In response, some ZKVMs have adopted a compilation pipeline that generates the RISC-V binary within a Docker container. This is a smart move, as it controls many factors that can affect builds. But it may not be enough:
Existing container technologies (like Docker) do not provide reproducibility: they are neither deterministic nor portable, as many details of the host OS and processor microarchitecture are directly visible inside the container. — Navarro Leija & al
Projects like Hermit aim to offer precise control over program execution, which could allow Bob to verify Alice’s program and ensure that the verifier is indeed the same. We would love to see these tools used more frequently in the production of RISC-V binaries for ZKVM deployments.
But this is the optimistic scenario: Bob has a clear incentive to verify Alice’s work since it’s a strict requirement for his participation in the game, as he will also need to provide a proof himself when it’s his turn.
A more concerning scenario involves a single-party prover, such as a manager of a portfolio, who might be the only one producing proofs supposedly based on a high-level program, without any oversight of their compilation process. In such cases, participants may be unaware of discrepancies between what the proofs actually verify (execution of a particular assembly code) and what they think the proofs are verifying (execution of a high-level program). We should make sure in every case not to let provers prove the wrong program.
Can proofs based on a RISC-V VM offer a high degree of security? That’s unlikely.
Compilation bugs
Let’s assume, for the sake of discussion, that we’ve solved the issues of reproducible builds and can deterministically compile a high-level program to RISC-V. Further, let’s imagine we have a formally verified RISC-V ZKVM that operates flawlessly, adhering strictly to the ISA specification. Are we done?
Unfortunately, no. Modern compilers often introduce bugs where the binary (RISC-V assembly, in our case) does not accurately reflect the original high-level code. One frequent source of such bugs is peephole optimization, where the compiler identifies patterns in the generated assembly and rewrites them to be more efficient. When this transformation breaks equivalence, we get a bug. Consider the example of LLVM bug 96366:
declare void @mumble(i32)
define i32 @f(i32 %0) {
%2 = sub nuw i32 0, %0
call void @mumble(i32 %2)
%3 = sub i32 1, %0
%4 = sub i32 3, %0
%5 = mul i32 %0, 1
%6 = add i32 %3, %5
%7 = add i32 %6, %4
ret i32 %7
}
This LLVM IR function computes f(x) = 4 - x, but due to the bug, the compiler translated it to f(x) = 4, in a misguided attempt to simplify intermediary variables.
In a typical setting, this kind of bug is relatively harmless because code is often unit-tested, and expected inputs and outputs are easy to verify. However, in a scenario like a Battleship game using a ZKVM, the prover doesn’t reveal their inputs (i.e., the position of their ships), making it far harder to detect errors. The only observable result might be a salvo of torpedoes that never results in hits, with no clear indication that something is wrong.
We already know these types of bugs happen. For example, Certora discovered a similar bug during an audit before deploying Aave contracts on ZKSync. Identifying the bug required manual inspection of the generated assembly and several days of investigation involving four institutions. Yet the bug was fairly dramatic (clearing a whole range of registers) and no malicious intent was reported. One might wonder at what this might look like in an adversarial context?
The frequency of compilation bugs
To understand how often these bugs occur, we can refer to some studies on the most popular compilers. For instance, in An empirical study of optimization bugs in GCC and LLVM by Zhou et al, the authors analyzed data from the GCC and LLVM projects over several years (ending in 2019) to collect confirmed and fixed bugs, specifically focusing on optimization bugs.
This is crucial because not every bug is exploitable in our context: they may lead to a simple crash, which is is unlikely to result in a wrongly verified proof. We’re particularly interested in mis-optimization bugs, which have a high likelihood of resulting in exploits. In such cases, an attacker could create a proof that appears to match the high-level program’s semantics but actually follows the mis-optimized semantics. These aren’t the only exploitable mis-compilation bugs, but we think mis-optimization bugs may have a significant intersection with exploitable bugs.
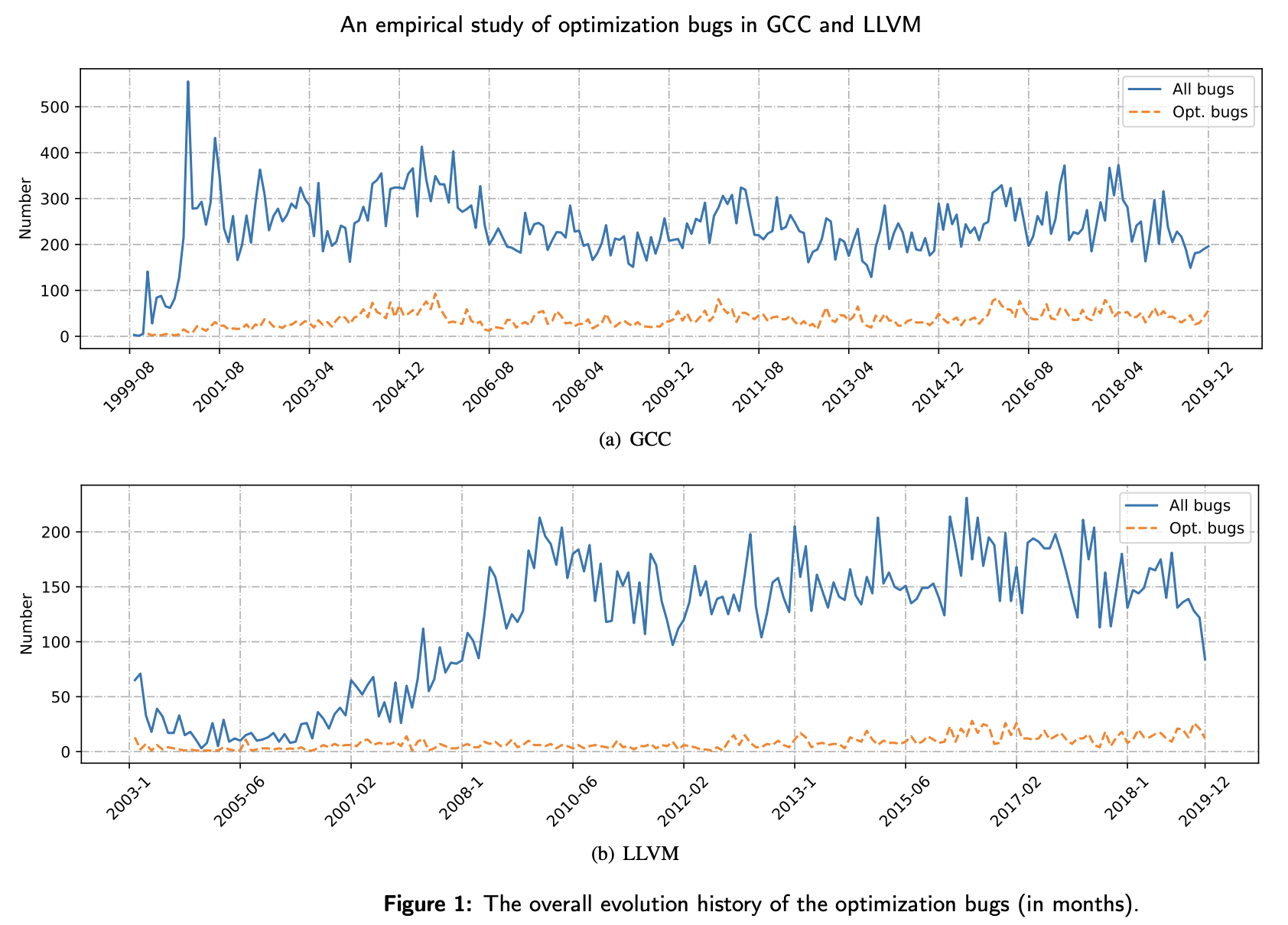
Generally, we obtain 57,591 GCC bugs and 22,748 LLVM bugs, which account for 66.17% and 52.49% of all bugs in GCC and LLVM, respectively. In particular, we collect 8,771 GCC optimization bugs and 1,564 LLVM optimization bugs. These optimization bugs account for 76.28% and 55.40% of all optimization bugs in GCC and LLVM, respectively, which indicates that the selected optimization bugs are representative. In addition, we manually classify the 10,335 optimization bugs into Crash, Misoptimization, and Performance
The results show that most of the optimization bugs in both GCC and LLVM belong to Mis-opt bugs, accounting for 57.21% and 61.38% respectively. However, in both compilers, the bug-fixing rate of Mis-opt bugs is smaller than those of Crash bugs and Performance bugs. — Zhou et al, ibid.
In that context, the figure shows that at least a dozen optimization bugs are reported in each of GCC and LLVM each month, with most being mis-optimizations—bugs that could lead to exploitable code in a proof system that hides inputs.
These bugs often remain unresolved for a long time:
On average, optimization bugs live over five months, and it takes 11.16 months for GCC and 13.55 months for LLVM to fix an optimization bug. — Zhou et al, ibid.
Other sources, such as Sun et al., 2016, provide additional insights into the frequency of compiler bugs. While these results are somewhat dated, we should note that bug reporting frequency has increased since the period covered in the studies.
Even with conservative estimates, every month, there should be at least a dozen new known vulnerabilities likely to lead to an exploit in a formally verified RISC-V ZKVM, where proofs are verified against assembly generated by one of the two major compilers (GCC or LLVM). This does not count unreported bugs.
Certified compilation to the rescue ?
While mainstream compilers may not be reliable enough to produce trustworthy assembly, there are better alternatives, such as certified compilation. The CompCert project offers a formally verified compiler that ensures the preservation of a wide range of semantics during the compilation process. Although it’s free only for non-commercial use and limited to a subset of the C programming language, CompCert includes a RISC-V 32-bit backend that could provide strong guarantees for the correctness of compiled assembly.
CompCert claims it produces binaries that run about 10% slower than those generated by GCC at optimization level 1. However, there are two factors to consider:
- Most modern RISC-V ZKVMs benchmark their performance code compiled at the more aggressive (and default) optimization level 3. How much of a setback would going back to level 1 represent?
- The performance of native execution doesn’t always correlate directly with proving performance.
We would love to see certified compilation used more widely for RISC-V ZKVMs, as well as benchmarks to validate the performance of this approach.
Conclusion
RISC-V-based ZKVMs have revolutionized developer productivity by enabling rapid prototyping of zero-knowledge proofs using familiar toolchains. By leveraging widely-used ISAs and existing libraries, they allow for fast proof development and the reuse of existing codebases.
However, challenges remain, particularly around performance optimization, reproducibility, and security. Miscompilation bugs and the complexity of achieving reproducible builds continue to pose significant issues. As promising as RISC-V ZKVMs are, ensuring their safety and security will require ongoing research and the adoption of more rigorous techniques, such as certified compilation.
Formally verifying a RISC-V ZKVM, on its own, would not be sufficient to ensure the security of a proof of a compiled EVM’s execution.
We hope that by initiating work on a formally-verified RISC-V ZKVM, the Ethereum Foundation has started a research effort to address these challenges, perhaps including developing a reference implementation of the EVM in C, acquiring a license for the Compcert compiler, or perhaps even formally verifying a compilation toolchain from Go to RISC-V. As proponents and practitioners of formal verification, nothing would make us happier than the see the Ethereum Foundation take such an ambitious step towards a more secure and reliable ZKVM ecosystem.
At Argument, we are exploring another model of ZKVM that bypasses compilation entirely by directly interpreting the high-level source language through a minimalistic abstract machine. We have recently demonstrated that this approach can be successfully redeveloped on top of an existing cryptographic prover, and can outperform competing RISC-V-based ZKVMs. We’ll share more about it soon, and we invite you, dear reader, to be part of the team that helps bring this project to a wider audience.